知識搜尋Agent 模板
知識搜尋 Agent 模板提供一套標準化的「檢索+強化生成 (RAG)」流程,協助您從本地或雲端知識來源中快速搜尋相關內容,並利用大型語言模型產生結構化、精準或摘要式的回覆。透過可視化的流程組裝與預先設定的節點配置,使用者無需撰寫任何程式碼,即可輕鬆建立企業級的知識查詢 Agent。
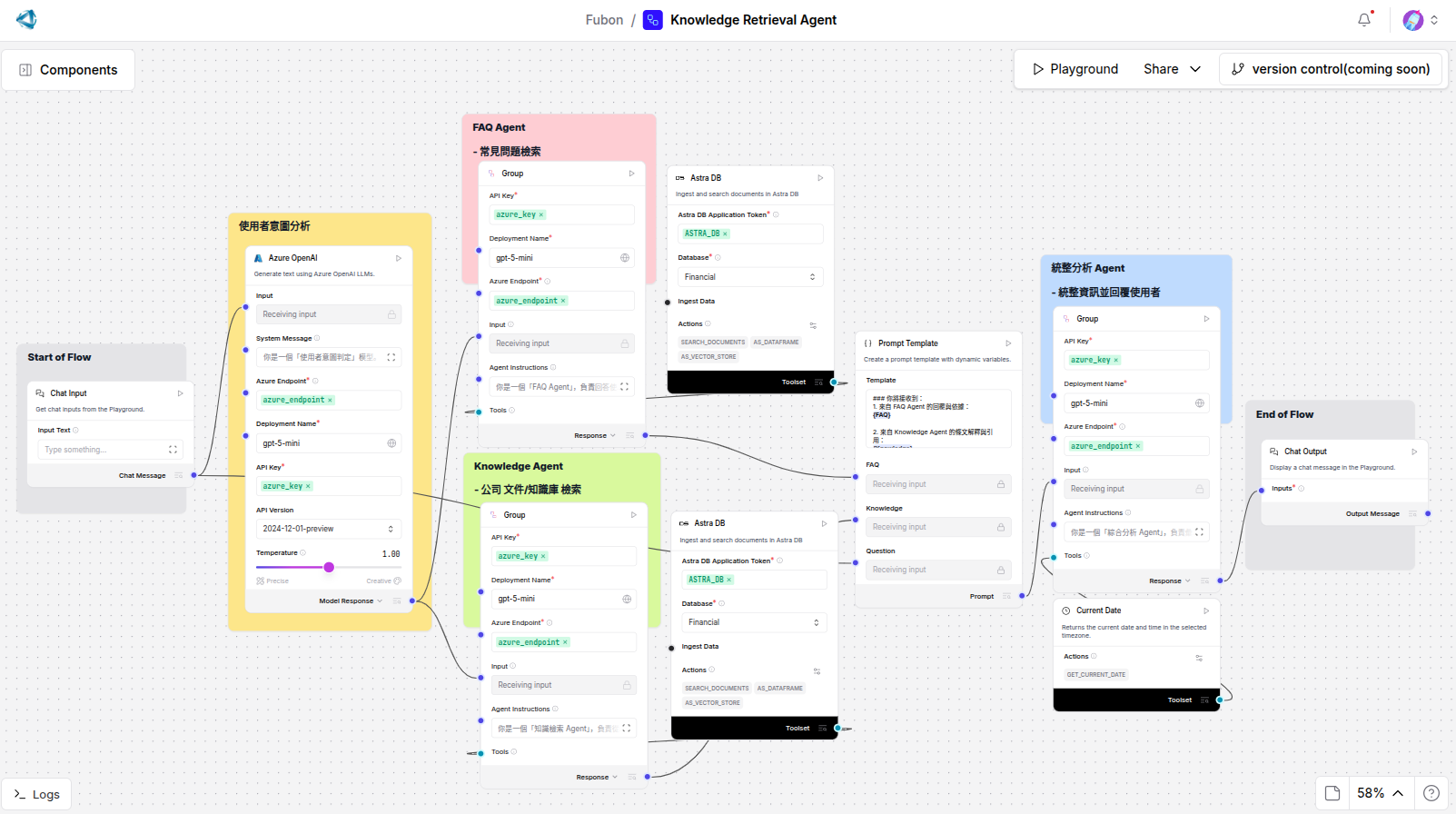
上圖展示整體流程:使用者輸入 → Query 處理 → 檢索相關內容 → 生成摘要/回答 → 回傳最終回覆與來源引用。
模板用途
此 Agent 模板用來支援「知識庫/企業文件搜尋」場景:使用者輸入問題或關鍵字,Agent 透過檢索 Components 尋找相關內容,再由語言模型產生可信且可追溯的回覆。特別適用於:
| 用途類型 | 說明 | 典型資料來源 |
|---|---|---|
| 企業 FAQ 擴充 | 員工或客戶常見問答集中管理 | FAQ 文件、政策公告 |
| 內部知識速查 | SOP、制度、法遵條款即時查詢 | PDF、Word、Markdown |
| 技術/產品文件搜尋 | API、版本更新、操作指南 | 技術白皮書、版本說明 |
| 文件摘要/比較 | 多篇文件整合總結或差異分析 | 研究報告、方案提案 |
| 客服支援前置 | 先自動知識檢索,降低人工負載 | 產品手冊、故障排除流程 |
使用者輸入 →(可選)Query 重寫/擴充 → 向量/索引檢索 → 回傳片段 → LLM 整合生成 → Chat Output 顯示
逐步說明:
-
Chat Input:使用者輸入自然語言問題(此階段僅收集原始意圖,尚未做語意調整;盡量保持輸入簡潔並避免貼入過長未結構化段落)。
-
Query 前處理(可選):針對原始輸入進行語意強化(抽取關鍵詞、補充同義詞、加入時間/範圍條件、過濾噪音字)。下圖示意:介面提供即時欄位讓使用者或系統在送往檢索前調整 Query,降低語意模糊及提升召回精準度。
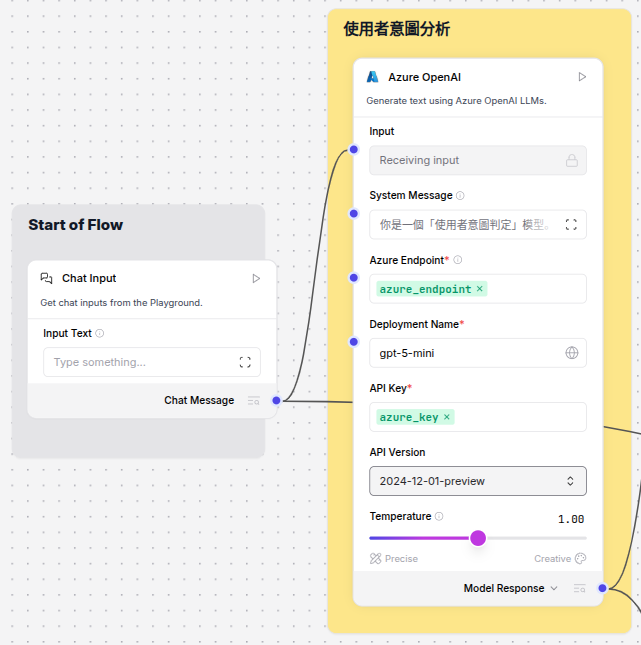
-
檢索:經過前處理後的 Query 送入向量或全文檢索節點,取得前 N 個相關片段(含 Metadata:來源、標題、段落位置、相似度分數)。下圖展示檢索與結果整理:重點在片段排序與分數閾值過濾(
score_threshold),若結果為空可啟動 fallback(降低門檻或改以關鍵字搜尋)。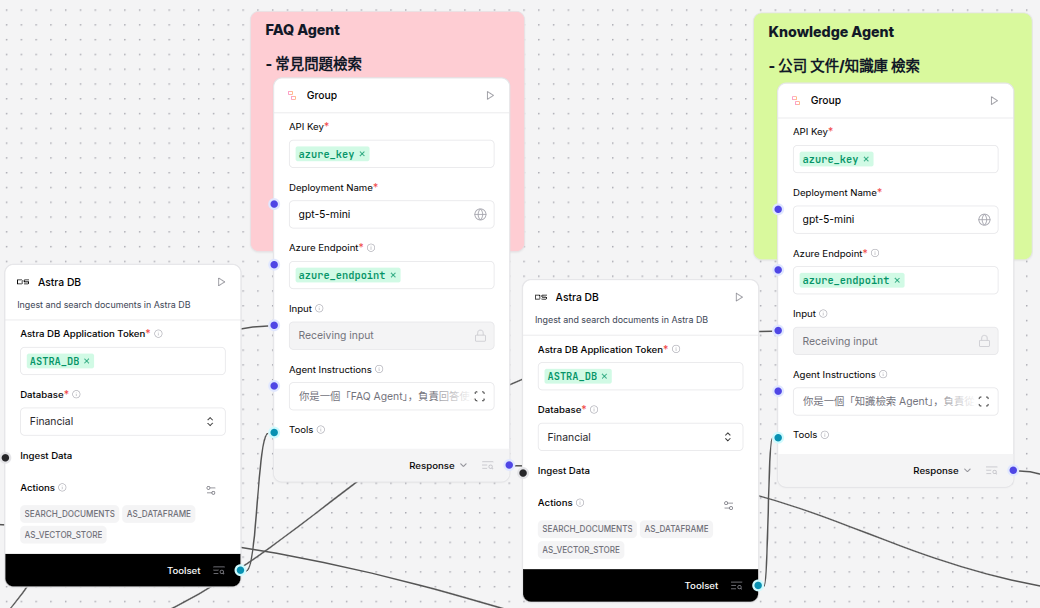
-
上下文組裝:檢索片段與 FAQ 結果(若有)被送入 Prompt Template,明確標記各來源區塊與使用者原始問題,確保 LLM 僅在提供的範圍內推論並降低幻覺風險。
-
回覆生成:LLM 彙整多來源片段,整合為結構化條列(摘要 / 比較 / 直接回答),同時附來源引用以支援追溯與後續審核。圖示顯示條列摘要形成過程。
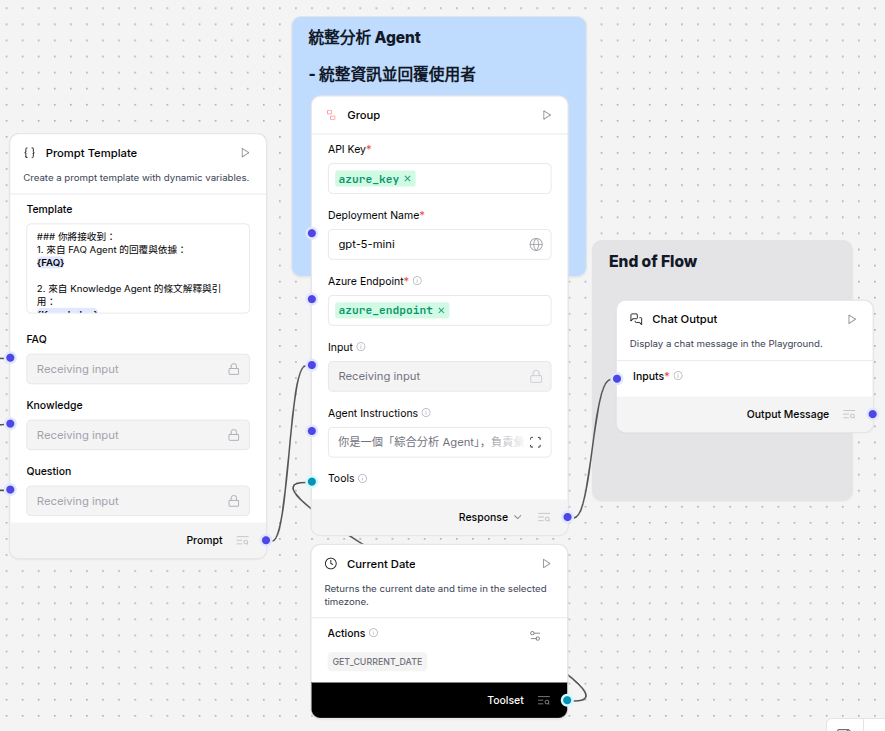
-
Chat Output:輸出最終回答與引用來源(可僅顯示前幾筆以維持清晰),同時保留
session_id以支援追問或多輪澄清。必要時可在此階段添加「使用者回饋」按鈕以迭代調整檢索策略。
可於 Playground 直接觀察節點資料流,快速迭代調整各參數。
範本節點與設定說明
| 節點名稱 | 用途說明 | 關鍵/建議設定 | 初學者提示 |
|---|---|---|---|
| Start of Flow → Chat Input | 入口:使用者自然語言查詢 | Input Text 可保持空白供互動輸入 | 避免一次放過長上下文,改逐步追問 |
| 語言模型節點 (Yellow) | 初步理解或直接生成(無檢索時 fallback) | model_provider, llm_model, temperature=0.2 | 先確保 API Key & 部署名稱正確 |
| 知識庫搜尋節點 (Green) | 執行向量/全文檢索 | top_k=4, score_threshold=0.4, 動作=SEARCH_DOCUMENTS | 若無結果調低 score_threshold |
| FAQ Agent 節點 (Pink) | 專門 FAQ 流程(可選) | Agent Instructions, Tools=知識庫搜尋節點 | 專門回答常見問題,縮短回覆時間 |
| Prompt Template 節點 | 動態組裝上下文 | Template 可含 {FAQ} {Knowledge} {Question} | 加上「請引用來源」提升可信度 |
| Current Date 節點 | 注入當前日期/時間 | Action=GET_CURRENT_DATE | 用於時間敏感問題(例如「今年」) |
| Chat Output | 最終回覆呈現 | show_sources=true, response_format=default | 測試不同格式是否易讀 |
若流程中同時存在 FAQ Agent 與一般 Knowledge 檢索,可在 Prompt Template 中清楚區分兩者來源避免混淆。
核心組件總覽
| 類別 | Components | 功能 | 典型錯誤 | 調整策略 |
|---|---|---|---|---|
| 輸入 | Chat Input | 收集使用者問題 | 過長上下文導致 Token 浪費 | 切分上下文、保留關鍵詞 |
| 前處理 | Query Preprocessor | 重寫/擴充 Query | 重寫後語意偏離原意 | 限制重寫策略為 keyword+synonym |
| 檢索 | Vector / Document Search | 找出相關片段 | 無結果或全是噪音 | 調整 top_k / score_threshold |
| 生成 | LLM / Agent | 組合片段 + 回覆 | 幻覺、不引用來源 | 降低 temperature + 強制引用指令 |
| 組裝 | Prompt Template | 建構 LLM 輸入 | 變數遺漏或格式難讀 | 使用明確區塊與標題分隔 |
| 輸出 | Chat Output | 呈現回覆 + 來源 | 來源過多顯示雜亂 | 限制來源顯示前 N 個 |
使用步驟(快速上手)
1. 選擇模板
在「使用模板」面板中挑選「知識搜尋 Agent」,匯入後於 Flow 編輯器展開查看各節點連線。
2. 配置模型節點
輸入模型提供者參數(API Key、Endpoint、部署名稱,例如 gpt-5-mini),將 temperature 先設為 0.2 確保穩定。
3. 配置知識庫節點
設定資料來源(如 Astra DB Financial 資料庫),選擇檢索動作 SEARCH_DOCUMENTS 或向量模式 AS_VECTOR_STORE。確認已完成文件嵌入。
4. 調整 Prompt Template
範例:
_10請根據以下資料:_101. FAQ 節點結果:`{FAQ}`_102. 檢索片段摘要:`{Knowledge}`_103. 使用者問題:`{Question}`_10請以條列方式回覆,並引用來源(格式:來源:檔名)。若無相關資訊請明確回覆「目前知識庫沒有相關資料」。
5. Playground 測試
輸入測試查詢:
公司過去一年財務報告中有關 SaaS 收入增長的部分?
檢查:
- 檢索節點是否有返回片段?
- Prompt Template 組裝內容是否包含所有變數?
- 回覆是否含來源且無離題內容?
6. 調整與迭代
若結果不理想可調整:
top_k(增加召回或降低噪音)score_threshold(過高導致無片段,過低導致雜訊)- Prompt 語氣(要求「僅根據提供內容回答」)
- temperature(提高可讀性或創意,降低可靠性風險)
7. 部署整合
驗證穩定後,可將整個 Flow 部署至內部聊天介面或外部應用程式,支援即時查詢。
重要參數說明(速查表)
| 類別 | 參數 | 說明 | 建議初始值 |
|---|---|---|---|
| 檢索 | top_k | 返回片段數量 | 4 |
| 檢索 | score_threshold | 相似度最低分門檻 | 0.35~0.5 |
| 模型 | temperature | 創造性/穩定性調節 | 0.2~0.5 (知識型) |
| 模型 | max_tokens | 回覆最大長度 | 512~1024 |
| 摘要 | summary_style | 輸出風格(concise, detailed, bullet) | concise |
| 輸出 | show_sources | 是否顯示來源 | true |
| 會話 | session_id | 區分不同使用者上下文 | 自動或外部注入 |
- 建立文件前先做「段落切分 + 嵌入」確保粒度適中(100~400 tokens)。
- 對高頻欄位(如標題、標籤)加權或建立 metadata 索引提升精準度。
- 使用 Query 重寫可降低使用者語意模糊造成的檢索落差。
- 開啟來源引用讓使用者信任結果並便於追溯。
- 適時限制模型溫度,避免「幻覺」生成與不實推論。
擴充方向
- 加入「意圖分類」先判斷使用者需求(查詢/摘��要/比較)。
- 整合結構化資料(例如資料庫查詢結果)與非結構化文件再融合回答。
- 增加快取層(對熱門 Query 回覆做暫存)。
- 併入評分/回饋機制來持續優化檢索與回答品質。
模板應用場景範例
| 場景 | 使用者行為 | 典型價值 |
|---|---|---|
| 公司內部 FAQ | 員工查詢政策/福利/IT 流程 | 降低人力回覆成本 |
| 文件檢索輔助 | 查詢研究報告或技術白皮書摘要 | 快速定位重要段落 |
| 客服前置支援 | 客戶提問產品細節先自動檢索 | 縮短等待時間 |
| 內部培訓助手 | 詢問教材內容或題目解析 | 強化學習效率 |
| 法規與合規查核 | 查詢條款是否符合最新規範 | 降低風險 |
下一步
- 將您的內部文件批次嵌入至向量資料庫。
- 針對高頻問題做 Prompt 精調與範例 Few-Shot。
- 若需要更高可觀測性,可串接 Logging 與 Monitoring Components。
- 查看其他模板(例如:
內部人資Agent)以建立跨部門知識共用方案。
若您已完成初次部署,建議前往「開發 → 使用 AgentBuilder 資料類型」了解 Message 與 Metadata 的結構以支援更進階分析。
